 ByteArray字节数组扩展
ByteArray字节数组扩展
版本历史
| 版本 | 更新内容 |
|---|---|
| 1.0 (2021-04-02) | 初始版本 |
| 1.1 (2021-05-21) | 修复ReadWord、ReadDWord和ToHex的错误 |
| 1.2 (2021-12-13) | ToString方法调用了JAVA 8的函数 |
| 1.3 (2022-05-13) | 添加WriteToFile、ReadFromFile和DeleteFile方法添加 AddUTF8String、AddASCIIString、ReadUTF8String和ReadASCIIString方法添加 GetUTF8ByteSize方法 |
| 1.4 (2024-03-13) | 添加WriteToFileSync、ReadFromFileSync方法 |
| 1.5 (2024-07-24) | 添加CRC32属性添加 SetWordAt和SetDWordAt方法修复 ReadIndex属性未考虑Base设置的问题 |
| 1.6 (2025-02-17) | 添加ReadUTF8StringUntil、ReadASCIIStringUntil和RemoveBytes方法 |
下载和安装
- ByteArray扩展: de.ullisroboterseite.ursai2bytearray.aix
- 示例项目: ByteArrayTest.aia
开发动机
在技术应用或控制设备时,通常需要处理二进制数据。此扩展允许维护一个二进制数据字段(字节数组)。
UDP扩展已经可以处理字节数组,TCP客户端的更新将很快跟进。
功能概述
字节数组扩展允许对存储的数据进行顺序和随机访问。随机访问的索引基址(第一个元素的索引)可以使用Base属性设置。可能的值为1(App Inventor中常用)或0(Java或C中常用)。
组件以空数组开始,这意味着它不包含任何元素。可以使用以下方法添加元素:
AddByte(无符号8位数字[0..255])AddWord(无符号16位数字[0..65,536])AddDWord(无符号32位数字[0..4,294,967,296])
对于AddWord和AddDWord,MsbFirst属性定义了字节添加到数组的顺序(字节序)。可以使用Append方法将另一个字节数组的内容添加到数组中。
Fill函数用指定数量的指定值元素填充数组。InsertByteAt函数在指定位置插入一个字节,其他元素向后移动一个位置。RemoveByteAt删除指定位置的字节,后续字节向前移动。RemoveBytes删除指定数量的字节。可以使用SetByteAt函数更改一个字节。
Clear函数从字节数组中删除所有元素。
顺序访问使用ReadByte、ReadWord或ReadDWord函数完成。MsbFirst属性定义字节顺序。ReadIndex属性指定接下来将读取的数组中的位置。为了读取特定元素,也可以相应地设置ReadIndex。Available属性返回还可以读取多少字节。
ToString方法将数组内容返回为两位十六进制数字序列。使用ToHex可以将字节、字或双字转换为其十六进制表示。HexPrefix属性指定在十六进制数字前面放置哪个字符串,默认设置为”0x”。
可以使用以下方法插入和读取字符串:
AddUTF8String、AddASCIIStringReadUTF8String、ReadASCIIStringReadUTF8StringUntil、ReadASCIIStringUntil
UTF-8编码的字符串通常每个字符需要多个字节。GetUTF8ByteSize返回存储UTF-8字符串所需的字节数。
可以使用WriteToFile和ReadFromFile方法将内容写入文件或从文件读取。例如,如果通过UDP(URS AI2 UDP扩展)或MQTT(URS AI2 MQTT扩展)传输图像,它们不能直接插入到图像组件中。这里有助于将数据存储在临时中间文件中,并从那里加载到图像块中。
注意:两个函数都异步执行!文件操作的结束以及文件或数据的可用性由AfterFileWritten和AfterFileRead事件指示。AfterFileWritten返回写入文件的绝对路径。
WriteToFileSync和ReadFromFileSync方法用于同步写入或读取数据。这意味着函数在操作完成且文件或数据可用时返回。对于大量数据,这可能导致较长的响应时间。
可以使用DeleteFile删除(临时)文件。
注意: 文件名(路径)的约定对应于标准文件组件的约定。
属性
- Available 可用字节数
- 返回还可以顺序读取的字节数。
- Base 基址索引
- 获取或设置第一个项目的索引。可能的条目为1(App Inventor中常用)或0(Java或C中常用)。大于1的值转换为1,小于0的值转换为0。默认为1。
- CRC32 CRC32校验值
- 获取字节数组的CRC32值(参见Java CRC32)。
- HexPrefix 十六进制前缀
- 获取或设置十六进制表示的前缀(参见
ToString和ToHex)。默认设置为”0x”。 - MsbFirst 高位在前
- 获取或设置
AddWord和AddDWord函数的字节添加顺序,以及ReadWord和ReadDWord的字节读取顺序。默认为true。 - ReadIndex 读取索引
- 获取或设置继续顺序读取的位置。默认为
Base的值。 - Size 数组长度
- 获取存储的字节数。
- Version 版本
- 获取扩展的版本。
方法
- AddASCIIString 添加ASCII字符串(文本)
- 将指定字符串的US-ASCII(7位)编码附加到字节数组的末尾。无法在US-ASCII代码中表示的字符被替换为’?’。
- AddByte 添加字节(字节值)
- 将一个字节(无符号8位数字[0..255])添加到字节数组的末尾。
如果指定值小于0或大于255,则不添加该值,并触发Screen.ErrorOccurred事件,错误号为17200(”值超出范围”)。
- AddDWord 添加双字(双字值)
- 将一个双字(无符号32位数字[0..4,294,967,295])添加到字节数组的末尾。
MsbFirst属性定义字节顺序。
如果指定值小于0或大于4,294,967,295,则不添加该值,并触发Screen.ErrorOccurred事件,错误号为17200(”值超出范围”)。
- AddWord 添加字(字值)
- 将一个字(无符号16位数字[0..65,535])添加到字节数组的末尾。
MsbFirst属性定义字节顺序。
如果指定值小于0或大于65,535,则不添加该值,并触发Screen.ErrorOccurred事件,错误号为17200(”值超出范围”)。
- AddUTF8String 添加UTF8字符串(文本)
- 将指定字符串的UTF-8编码附加到字节数组的末尾。UTF-8编码的字符串通常每个字符需要多个字节。
GetUTF8ByteSize返回存储UTF-8字符串所需的字节数。 - Append 附加字节数组(数组)
- 添加指定字节数组的内容。
Array必须是UrsAI2ByteArray扩展的实例。
如果不是这种情况,则不添加,并触发Screen.ErrorOccurred事件,错误号为17202(”类型无效”)。
- Clear 清空()
- 从字节数组中删除所有元素。
ReadIndex属性重置为Base的值。 - DeleteFile 删除文件(文件名)
- 删除指定的文件(参见File.Delete)。
- Fill 填充(数量,值)
- 用数量字节填充字节数组,并赋值
Value。先前已包含的元素预先被删除(参见Clear)。ReadIndex属性重置为Base的值。Value必须是范围[0..255]内的无符号数字。
如果Value小于0或大于255,则不执行该函数,并触发Screen.ErrorOccurred事件,错误号为17200(”值超出范围”)。
- GetByteAt 获取字节(索引)
- 获取位置
Index处的项目的值。
如果Index的值小于Base或指向数组后面,则触发Screen.ErrorOccurred事件,错误号为17201(”索引超出范围”),并返回值0。
- GetUTF8ByteSize 获取UTF8字节大小(文本)
- 返回存储UTF-8字符串所需的字节数。UTF-8编码的字符串通常每个字符需要多个字节。
- InsertByteAt 在位置插入字节(索引,字节值)
- 在指定的
Index位置插入一个字节。后续元素向后推。如果ReadIndex指向插入点后面,它也会移动,以便指向与插入前相同的值。
如果Index的值小于Base或Base在数组后面,则不执行该函数,并触发Screen.ErrorOccurred事件,错误号为17201(”索引超出范围”)。
- ReadASCIIString 读取ASCII字符串()
- 从当前位置到结尾顺序读取US-ASCII(7位)字符串。
- ReadASCIIStringUntil 读取ASCII字符串直到(分隔符)
- 从当前位置顺序读取US-ASCII(7位)字符串,直到找到分隔字符/字符串。支持以下转义序列:\n、\r和\t(由代码生成器提供)以及来自扩展的\0(null)。
- ReadByte 读取字节()
- 获取
ReadIndex指向的元素的值。ReadIndex递增。
如果没有更多字节可用(参见Available),则触发Screen.ErrorOccurred事件,错误号为17203(”读取超出数组末尾”),并返回值0。
- ReadDWord 读取双字()
- 获取
ReadIndex指向的双字(4字节)。MsbFirst属性定义字节顺序。ReadIndex递增。
如果没有足够的字节可用(参见Available),则触发Screen.ErrorOccurred事件,错误号为17203(”读取超出数组末尾”),并返回值0。
- ReadFile 读取文件(文件名)
- 将指定文件的内容附加到字节数组的末尾(参见File.ReadFrom)。数据的可用性由
AfterFileRead事件指示。 - ReadFromFileSync 同步读取文件(文件名)
- 将指定文件的内容附加到字节数组的末尾(参见File.ReadFrom)。该函数在文件完全读取后返回。
- ReadUTF8String 读取UTF8字符串()
- 从当前位置到结尾顺序读取UTF8字符串。
- ReadUTF8StringUntil 读取UTF8字符串直到(分隔符)
- 从当前位置顺序读取UTF8字符串,直到找到分隔字符/字符串。支持以下转义序列:\n、\r和\t(由代码生成器提供)以及来自扩展的\0(null)。
- ReadWord 读取字()
- 获取
ReadIndex指向的字(2字节)。MsbFirst属性定义字节顺序。ReadIndex递增。
如果没有足够的字节可用(参见Available),则触发Screen.ErrorOccurred事件,错误号为17203(”读取超出数组末尾”),并返回值0。
- RemoveByteAt 移除字节(索引)
- 删除指定位置的字节。后续字节向前移动。
如果Index的值小于Base或指向数组后面,则不执行该函数,并触发Screen.ErrorOccurred事件,错误号为17201(”索引超出范围”)。
- RemoveBytes 移除字节(索引,数量)
- 从指定位置开始移除指定数量的字节。
- SetByteAt 设置字节(索引,字节值)
- 在指定位置设置字节的值。
如果Index的值小于Base或指向数组后面,则不执行该函数,并触发Screen.ErrorOccurred事件,错误号为17201(”索引超出范围”)。
- SetDWordAt 设置双字(索引,双字值)
- 在指定位置设置双字的值。
MsbFirst属性定义字节顺序。 - SetWordAt 设置字(索引,字值)
- 在指定位置设置字的值。
MsbFirst属性定义字节顺序。 - ToHex 转十六进制(数值,位数)
- 将无符号数字转换为其十六进制表示。如果位数无效或值超出范围,返回”-“。
- ToString 转字符串()
- 将整个字节数组转换为两位十六进制数字序列。
- WriteToFile 写入文件(文件名)
- 将字节数组的内容写入指定的文件(参见File.SaveTo)。写入操作的结束和文件的可用性由
AfterFileWritten事件指示。 - WriteToFileSync 同步写入文件(文件名)
- 将字节数组的内容写入指定的文件(参见File.SaveTo)。该函数在文件完全写入后返回。
事件
- AfterFileRead 文件读取完成时(文件名)
- 文件读取操作完成时触发。
- AfterFileWritten 文件写入完成时(文件名,文件路径)
- 文件写入操作完成时触发。参数包括文件名和文件的绝对路径。
使用示例
基本字节数组操作

示例应用界面
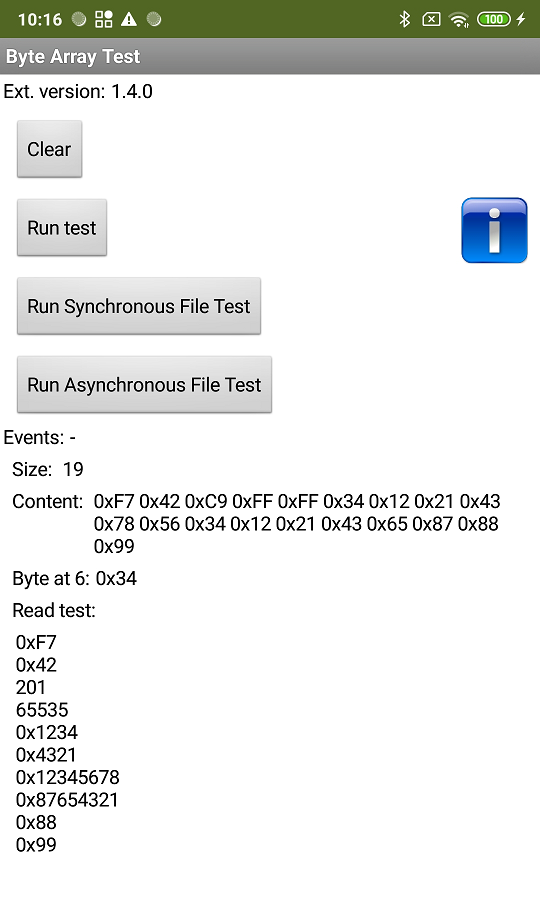
积木示例
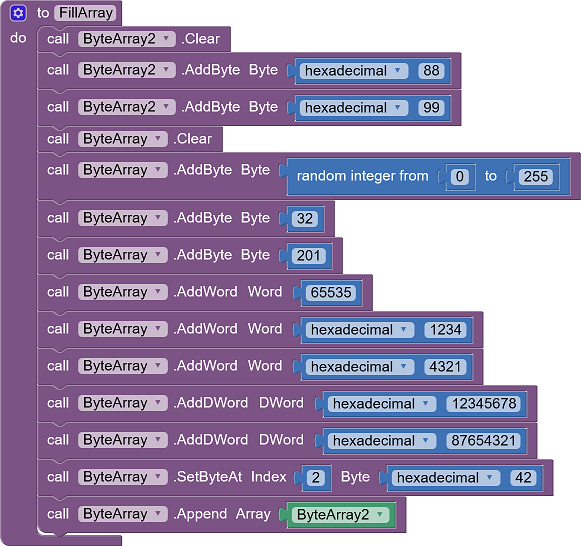
基本用法
// 创建字节数组并添加数据
when Button1.Click
do
// 清空数组
call ByteArray1.Clear
// 添加不同类型的数据
call ByteArray1.AddByte 65 // 字符 'A'
call ByteArray1.AddWord 12345 // 16位整数
call ByteArray1.AddDWord 1234567890 // 32位整数
// 显示数组信息
set Label1.Text to "数组长度: " & ByteArray1.Size
set Label2.Text to "可用字节: " & ByteArray1.Available
字符串处理
// UTF-8字符串处理
when Button2.Click
do
call ByteArray1.Clear
// 添加UTF-8字符串
call ByteArray1.AddUTF8String "Hello 世界"
// 计算UTF-8字节大小
set ByteSize to ByteArray1.GetUTF8ByteSize "Hello 世界"
// 重置读取位置并读取字符串
set ByteArray1.ReadIndex to ByteArray1.Base
set StringValue to ByteArray1.ReadUTF8String
set Label3.Text to "UTF-8字符串: " & StringValue & " (" & ByteSize & " 字节)"
文件操作
// 异步文件操作
when Button3.Click
do
call ByteArray1.Clear
call ByteArray1.AddString "这是要保存到文件的内容"
// 异步写入文件
call ByteArray1.WriteToFile "/sdcard/test.txt"
// 文件写入完成事件
when ByteArray1.AfterFileWritten fileName
do
show notification "文件已写入: " & fileName
// 读取文件内容
call ByteArray1.Clear
call ByteArray1.ReadFile "/sdcard/test.txt"
// 文件读取完成事件
when ByteArray1.AfterFileRead fileName
do
// 重置读取位置
set ByteArray1.ReadIndex to ByteArray1.Base
set FileContent to ByteArray1.ReadString
set Label4.Text to "文件内容: " & FileContent
十六进制转换
// 十六进制转换
when Button4.Click
do
call ByteArray1.Clear
call ByteArray1.AddByte 255
call ByteArray1.AddWord 65535
call ByteArray1.AddDWord 4294967295
// 转换为十六进制字符串
set HexString to ByteArray1.ToString
// 单个值转换
set Hex1 to ByteArray1.ToHex 255 2 // "0xFF"
set Hex2 to ByteArray1.ToHex 65535 4 // "0xFFFF"
set Label5.Text to "十六进制: " & HexString
网络数据包构建
// 构建网络数据包
when Button5.Click
do
call ByteArray1.Clear
// 设置大端序(网络字节序)
set ByteArray1.MsbFirst to true
// 添加数据包头
call ByteArray1.AddWord 1234 // 包类型
call ByteArray1.AddDWord 5678 // 序列号
call ByteArray1.AddWord length of global_DataList // 数据长度
// 添加数据负载
for each item in global_DataList
call ByteArray1.AddByte item
// 获取完整的字节数组用于网络传输
set NetworkData to ByteArray1.ToString
常见应用场景
1. 网络通信
- 构建和解析网络协议数据包
- TCP/UDP通信的数据处理
- MQTT、HTTP等协议的二进制数据处理
2. 文件格式处理
- 图片、音频、视频文件的读写
- 自定义文件格式的创建和解析
- 配置文件的二进制处理
3. 设备控制
- 串口通信数据处理
- 蓝牙数据包处理
- IoT设备的数据交互
4. 数据加密
- 简单的加密算法实现
- 数据完整性校验(CRC32)
- 二进制数据的编码解码
5. 协议实现
- Modbus、CAN总线等工业协议
- 自定义通信协议
- 设备间的数据交换
错误代码
| 错误代码 | 错误信息 | 含义 |
|---|---|---|
| 17200 | Value out of range | 值超出范围(字节值<0或>255) |
| 17201 | Index out of range | 索引超出范围 |
| 17202 | Invalid type | 类型无效 |
| 17203 | Read beyond end of array | 读取超出数组末尾 |
最佳实践
- 索引管理: 注意Base属性的设置(1或0),确保索引计算正确
- 字节序: 在网络通信中使用大端序(MsbFirst=true)
- 错误处理: 监听ErrorOccurred事件处理可能的错误
- 文件操作: 大文件操作时考虑使用异步方法
- 内存管理: 大量数据处理时注意内存使用情况
- 字符串编码: 明确使用ASCII或UTF-8编码,避免乱码
本文档基于UrsAI2ByteArray扩展官方文档整理,更多信息请访问ullisroboterseite.de。
 扫码添加客服咨询
扫码添加客服咨询

